English
¡Enhorabuena! Tu nuevo proyecto sobre una base de datos noSQL está listo para salir a producción. Tu entorno de desarrollo, con un solo nodo, ha sido realmente simple de instalar, configurar y utilizar. Pero … un momento …
¿Aguantará tu entorno los requerimientos de producción del sistema? ¿Has pensado en un posible fallo de una máquina? ¿Has probado un volumen de datos comparable al de producción? ¿Confías en soportar la carga de usuarios concurrentes requerida?
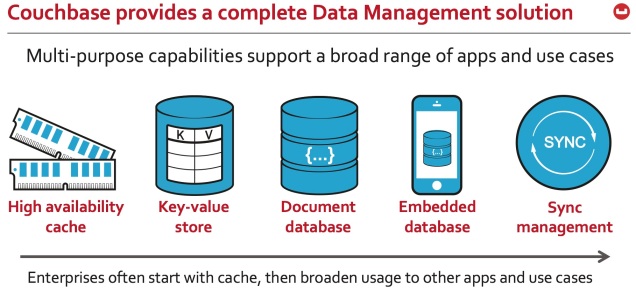
Si pensabas salir a producción con un entorno de un solo nodo probablemente te equivocas. Necesitas un entorno de producción en condiciones. Necesitas un cluster.
En esta entrada haremos una comparación del esfuerzo necesario para configurar un entorno de producción en cluster con dos bases de datos noSql muy populares: MongoDB y Couchbase.
Para este ejercicio, vamos a configurar un entorno de producción en cluster con los siguientes requerimientos:
- Los datos se distribuirán de uniformemente en tres particiones (shards)
- El cluster debe soportar el fallo de un nodo sin pérdida de datos ni pérdida de servicio
- El cluster soportará el balanceo de peticiones de clientes externos
- Seguiremos la documentación oficial del fabricante para ambos productos, MongoDB y Couchbase
Para los que no os gusta esperar, vamos a mostrar los resultados en una tabla y un resumen a continuación. Después entraremos en detalles:
|
 |
 |
|
Número de máquinas requeridas
|
14
|
3
|
| Balanceador
de carga
|
1
|
No requerido
|
|
Número de comandos ejecutados
|
128
|
27
|
|
Número de ficheros editados
|
28
|
0
|
Las arquitecturas desplegadas son estas:
Resumen
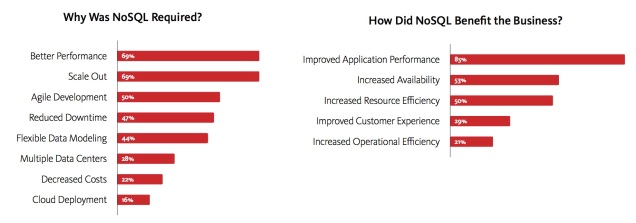
Con esta comparación, que corresponde a una instalación siguiendo la documentación oficial de MongoDB y Couchbase, es fácil comprobar las diferencias entre ambas aproximaciones desde el punto de vista operacional. Es mucho más fácil crear, administrar y operar Couchbase, con un número de servidores sensiblemente inferior, y con un reflejo inmediato en los costes de operación.
Con Couchbase es también más sencillo configurar réplica de clusters entre Centros de Datos separados geográficamente para soportar recuperación ante desastres y alta disponibilidad.
Desde un punto de vista de desarrollo, con MongoDB es necesario activar sharding al nivel de database y de collection. Además, para conseguir que los datos se repartan de manera uniforme entre los servidores es necesario elegir cuidadosamente la sharding key, lo que no resulta sencillo, y no puede ser cambiado después de la inserción de datos [1] [2].
Para tener una idea de esta complejidad con MongoDB, observamos en la documentación de MongoDB, que mantenemos en el ingles original [3]:
IMPORTANT
It takes time and resources to deploy sharding. If your system has already reached or exceeded its capacity, it will be difficult to deploy sharding without impacting your application.
As a result, if you think you will need to partition your database in the future, do not wait until your system is over capacity to enable sharding.
[IMPORTANTE
Desplegar sharding requiere tiempo y recursos. Si tu sistema ya ha alcanzado o excedido su capacidad, va a resultar difícil desplegar sharding sin impactar a la aplicación.
Como resultado, si piensas que tu base de datos va a necesitar particionamiento en el futuro, no esperes a que tu sistema exceda su capacidad para activar sharding]
Detalles de arquitectura
Arquitectura con MongoDB
En la configuración de la arquitectura estamos siguiendo la documentación de MongoDB:
De acuerdo a estas recomendaciones y a nuestros requerimientos iniciales:
- Necesitaremos tres Config Servers, cada uno desplegado en su propia máquina.
- El punto de entrada de los clientes es el proceso Router (mongos). Utilizaremos dos Routers, cada uno en su propia máquina.
- Necesitaremos un balanceador de carga con afinidad de cliente. [NOTA: como alternativa a los puntos 2 y 3, podemos desplegar una instancia mongos en cada servidor de aplicaciones]
- Utilizaremos tres shards, con un Replica Set en cada uno.
- Cada Replica Set contendrá tres instancias mongod, cada una en su propia máquina. En total utilizaremos 9 máquinas para sharding (3 shards x 3 mongod/shards x 1 máquina/mongod)
Nuestra arquitectura con MongoDB se muestra en la siguiente figura:
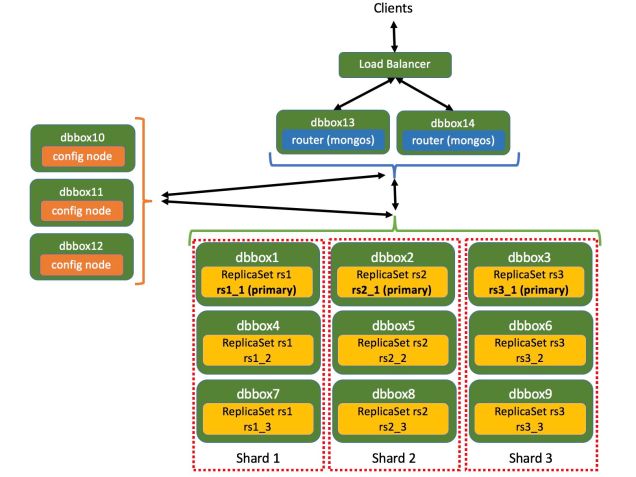
- Cada Replica Set tiene tres procesos (mongod), cada uno ejecutándose en una máquina diferente. Uno de ellos actúa como nodo primario, y se encarga de la escritura de datos, y los otros dos actúan como nodos de réplica, almacenando copias de los datos para soportar alta disponibilidad en caso de caída del nodo primario
- Cada shard es responsable de un subconjunto de los datos. El modo de particionamiento se basa en utilizar una sharding key o por un algoritmo de hash para las claves de los documentos.
- Desplegaremos un Replica Set en cada shard [5].
- El acceso a la base de datos se realiza mediante nodos de enrutado (mongos).
- Los clientes se comunican con los mongos a través de un balanceador de carga con afinidad de cliente.
Con este despliegue necesitamos catorce máquinas y un balanceador de carga.
Arquitectura con Couchbase
Estamos siguiendo la siguiente documentación de Couchbase:
De acuerdo a estas recomendaciones y a nuestros requerimientos iniciales:
- En Couchbase, cada keyspace se llama bucket, y lo podemos asimilar a una instancia de base de datos. Cada bucket se divide en un número fijo de particiones (1024), que llamamos vBuckets. Los vBuckets se distribuyen de forma uniforme entre los distintos nodos del cluster. Si pretendemos tener los datos en tres shards, necesitaremos tres nodos, cada uno ejecutándose en una máquina dedicada. De este modo, cada nodo almacena la tercera parte de los datos.
- Los datos se distribuyen así de modo uniforme en los tres nodos.
- Cada documento se repica automáticamente a un nodo diferente del cluster, asegurando así la alta disponibilidad en caso de fallo de servidor.
- El enrutado del cliente al nodo correspondiente del cluster en cada interacción se realiza mediante la librería de acceso (Couchbase client SDK). No se requiere ningún nodo de enrutado ni balanceador de carga.
En nuestro caso, la arquitectura de cluster con Couchbase queda así:
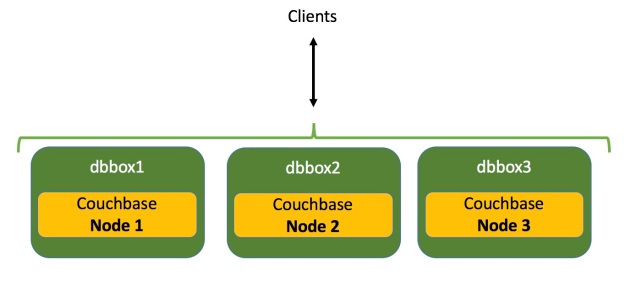
Con este despliegue necesitaremos tres máquinas.
Detalle de instalación de los entornos
Para este ejercicio utilizaremos 14 máquinas virtuales Linux CentOS 7, con 2 Gb RAM cada una.
Llamaremos a cada máquina: dbbox1, dbbox2, … dbbox14.
Para facilitar la instalación hemos utilizado IPs fijas y un mapeo nombre/IP en el fichero hosts (/etc/hosts) para todas las máquinas.
Instalación del cluster de MongoDB
Instalación de MongoDB
Instalamos MongoDB en las 14 máquinas. En cada máquina ejecutamos:
vi /etc/yum.repos.d/mongodb-org-3.0.repo
[EDIT FILE]>>>>
[mongodb-org-3.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.0/x86_64/
gpgcheck=0
enabled=1
<<<<
sudo yum install -y mongodb-org
vi /etc/selinux/config
[EDIT FILE]>>>>
SELINUX=disabled #SELINUX=enforcing
<<<<<
chkconfig mongod off
systemctl disable firewalld
reboot
Hemos ejecutado:
(6 comandos + 2 ficheros editados) x 14 máquinas = 84 comandos + 28 ficheros editados
Configuration Servers
En 3 máquinas (dbbox10, dbbox11, dbbox12)
mkdir -p /mongodb/config
export LC_ALL=C
mongod --configsvr --logpath /mongodb/config/log --logappend --dbpath /mongodb/config --fork
3 comandos x 3 máquinas = 9 comandos
Routers (mongos)
En dos machines (dbbox13, dbbox14)
mkdir /mongodb
mongos --configdb dbbox10:27019,dbbox11:27019,dbbox12:27019 --fork --logappend --logpath /mongodb
2 comandos x 2 máquinas = 4 comandos
Shards (mongod)
En nueve máquinas (dbbox1, dbbox2, …, dbbox9)
Primero configuramos los replica sets:
mkdir -p /mongodb/rs1_1
# Note different replica set and port for each process
mongod --shardsvr --replSet rs1 --dbpath /mongodb/rs1_1 --logpath /mongodb/log.rs1 --fork --logappend --smallfiles --oplogSize 50 --port 27001
(en cada máquina especificamos el nombre del replica set para reflejar la figura de arquitectura que hemos definido previamente, es decir los valores rs1, rs1_1 cambiarán a rs2, rs2_1, etc …)
2 comandos x 9 máquinas = 18 comandos
En dbbox1:
mongo --port 27001
> rs.initiate()
{
"info2" : "no configuration explicitly specified -- making one",
"me" : "dbbox1:27001",
"ok" : 1
}
rs1:OTHER> rs.add("dbbox4:27001")
{ "ok" : 1 }
rs1:PRIMARY> rs.add("dbbox7:27001")
{ "ok" : 1 }
3 comandos
En dbbox2:
mongo --port 27001
> rs.initiate()
{
"info2" : "no configuration explicitly specified -- making one",
"me" : "dbbox2:27001",
"ok" : 1
}
rs2:OTHER> rs.add("dbbox5:27001")
{ "ok" : 1 }
rs2:PRIMARY> rs.add("dbbox8:27001")
{ "ok" : 1 }
3 comandos
En dbbox3:
mongo --port 27001
> rs.initiate()
{
"info2" : "no configuration explicitly specified -- making one",
"me" : "dbbox3:27001",
"ok" : 1
}
rs3:OTHER> rs.add("dbbox6:27001")
{ "ok" : 1 }
rs3:PRIMARY> rs.add("dbbox9:27001")
{ "ok" : 1 }
3 comandos
Configuración Shards:
En dbbox10:
mongo
mongos> sh.addShard("rs1/dbbox1:27001")
{ "shardAdded" : "rs1", "ok" : 1 }
mongos> sh.addShard("rs2/dbbox2:27001")
{ "shardAdded" : "rs2", "ok" : 1 }
mongos> sh.addShard("rs3/dbbox3:27001")
{ "shardAdded" : "rs3", "ok" : 1 }
4 comandos
Chequeo de configuración:
mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("5612784c13c13614cd1e823b")
}
shards:
{ "_id" : "rs1", "host" : "rs1/dbbox1:27001,dbbox4:27001,dbbox7:27001" }
{ "_id" : "rs2", "host" : "rs2/dbbox2:27001,dbbox5:27001,dbbox8:27001" }
{ "_id" : "rs3", "host" : "rs3/dbbox3:27001,dbbox6:27001,dbbox9:27001" }
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
Total:
128 comandos
28 ficheros editados
Instalación del cluster de Couchbase
Instalación de Couchbase
Instalamos Couchbase en tres máquinas (dbbox1, dbbox2, dbbox3). En cada máquina ejecutamos:
# Disable swappiness
sudo echo 0 > /proc/sys/vm/swappiness
sudo echo '' >> /etc/sysctl.conf
sudo echo '#Set swappiness to 0 to avoid swapping' >> /etc/sysctl.conf
sudo echo 'vm.swappiness = 0' >> /etc/sysctl.conf
# Disable THP
sudo echo never > /sys/kernel/mm/transparent_hugepage/enabled
sudo echo never > /sys/kernel/mm/transparent_hugepage/defrag
# Download binary
wget http://packages.couchbase.com/releases/4.0.0/couchbase-server-enterprise-4.0.0-centos7.x86_64.rpm
sudo rpm --install couchbase-server-enterprise-4.0.0-centos7.x86_64.rpm
8 comandos x 3 máquinas = 24 comandos
Configuración del Cluster
Aunque esto se puede hacer desde un navegador accediendo a la console da administración, en este ejercicio lo haremos por línea de comando.
Esto se puede hacer desde una sola máquina (dbbox1).
El primer comando inicializa el cluster. El segundo comando añade el nodo 2 al cluster. El tercer comando añade el nodo 3 al cluster.
/optó/couchbase/bin/couchbase-cli cluster-init -c dbbox1.mysite.com:8091 -u Administrator -p change_it --cluster-username=Administrator --cluster-password=change_it --cluster-ramsize=256 --services=data,index,query
/opt/couchbase/bin/couchbase-cli server-add -c dbbox1.mysite.com:8091 –u Administrator –p change_it --server-add=dbbox2.mysite.com:8091 --services=data,index,query
/opt/couchbase/bin/couchbase-cli server-add -c dbbox1.mysite.com:8091 -u Administrator -p change_it --server-add=dbbox3.mysite.com:8091 --server-add-username=Administrator --server-add-password=change_it --services=data,index,query
3 comandos
Total:
27 comandos
REFERENCIAS
[1] (MongoDB) Shard Keys – http://docs.mongodb.org/manual/core/sharding-shard-key/
[2] (MongoDB) Considerations for Selecting Shard Keys – http://docs.mongodb.org/manual/tutorial/choose-a-shard-key/
[3] (MongoDB) Sharded Cluster Requirements –
http://docs.mongodb.org/manual/core/sharded-cluster-requirements/
[4] (MongoDB) Production Cluster Architecture –
http://docs.mongodb.org/manual/core/sharded-cluster-architectures-production/
[5] (MongoDB) Deploy a Sharded Cluster –
http://docs.mongodb.org/manual/tutorial/deploy-shard-cluster/
[6] (MongoDB) Deploy a Replica Set –
http://docs.mongodb.org/manual/tutorial/deploy-replica-set/
[7] (Couchbase) Cluster Setup – http://developer.couchbase.com/documentation/server/4.0/clustersetup/manage-cluster-intro.html
[8] (Couchbase) Command Line Interface reference – http://developer.couchbase.com/documentation/server/4.0/cli/cli-intro.html
[9] (Couchbase) Client Toplogy Awareness – http://developer.couchbase.com/documentation/server/4.0/concepts/client-topology-awareness.html